[혼공분석] 6주차: 복잡한 데이터 표현하기
혼공단을 그만두기 너무~ 아쉬운 나머지..
아끼고 아끼다 일요일이 되어서야.. 마음을 다잡고.. 정리해 보는.. 6주 차..
Chapter 06. 복잡한 데이터 표현하기
06-1. 객체지향 API로 그래프 꾸미기
객체지향 API: 명시적으로 피겨 객체와 서브플롯 객체를 만들어 객체의 메서드를 사용하는 방식
→ 하나의 그래프를 간단하게 그릴 때는 pyplot 방식
→ 여러 개의 그래프를 그리거나 꾸밀 때는 객체지향 API 방식
#pyplot 방식
plt.plot([1, 4, 9, 16])
plt.title('simple line graph')
plt.show()
#객체지향 API 방식
fig, ax = plt.subplots()
ax.plot([1, 4, 9, 16])
ax.set_title('simple line graph')
fig.show()
그래프의 차이는 없지만 그리려 하는 그래프에 따라 방법 선택 !
→ 간단한 그래프를 그릴 것인가? 복잡한 그래프를 그릴 것인가?
그래프에 한글 출력하기
*미리 글꼴 다운로드 후 시스템에 추가해 놓기!
# 노트북이 코랩에서 실행 중인지 확인
import sys
if 'google.colab' in sys.modules:
!echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections
# 나눔 폰트를 설치
!sudo apt-get -qq -y install fonts-nanum
import matplotlib.font_manager as fm
font_files = fm.findSystemFonts(fontpaths=['/usr/share/fonts/truetype/nanum'])
for fpath in font_files:
fm.fontManager.addfont(fpath)#DPI 기본값 변경
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 100
폰트 지정하기: font.family 속성
#기본 폰트 나눔고딕으로 설정
plt.rcParams['font.family'] = 'NanumGothic'#현재 기본 폰트 확인
plt.rcParams['font.family']
폰트 지정하기: rc( ) 함수
plt.rc('font', family='NanumBarunGothic')#폰트 크기 설정
plt.rc('font', family='NanumBarunGothic', size=11)print(plt.rcParams['font.family'], plt.rcParams['font.size'])
plt.plot([1, 4, 9, 16])
plt.title('간단한 선 그래프')
plt.show()
출판사별 발행 도서 개수 산점도 그리기
*4장에서 만든 ns_book7 파일 불러와 실습 진행
import gdown
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
import pandas as pd
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
ns_book7.head()
top30_pubs = ns_book7['출판사'].value_counts()[:30] #value.conts() 메서드는 내림차순 정렬
top30_pubs
#isin() 메서드를 통해 상위 30개에 해당하는 출판사 True, 아닌 출판사 False 반환
top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index)
top30_pubs_idx
#True인 원소의 총 개수
top30_pubs_idx.sum()
sample( ) 메소드의 첫 번째 매개변수에서 무작위로 선택할 행 개수 지정
ns_book8 = ns_book7[top30_pubs_idx].sample(1000, random_state=42)
ns_book8.head()
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(ns_book8['발행년도'], ns_book8['출판사'])
ax.set_title('출판사별 발행 도서')
fig.show()
scatter( ) 함수의 s 매개변수: 마커 크기 변경 *기본값 6, rcParams['lines.markersize'] 제곱 사용
→ 입력 데이터와 동일한 길이의 배열 지정 시 각 데이터마다 마커의 크기가 다른 산점도 그릴 수 있음 !
scatter( ) 함수의 alpha 매개변수: 마커 투명도 변경
scatter( ) 함수의 edgecolor 매개변수: 마커 테두리 색 변경 *기본값 'face'(마커의 색)
scatter( ) 함수의 linewidths 매개변수: 마커 테두리 선 변경 *기본값 1.5
scatter( ) 함수의 c 매개변수: 산점도 색 변경
→ 데이터 개수와 동일한 길이의 배열 지정 시 각 데이터마다 다른 색깔로 그릴 수 있음 !
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(ns_book8['발행년도'], ns_book8['출판사'], s=ns_book8['대출건수']*2,
linewidths=0.5, edgecolors='k', alpha=0.3, c=ns_book8['대출건수'])
ax.set_title('출판사별 발행 도서')
fig.show()
값에 따라 색상 표현: 컬러맵
scatter ( ) 함수의 cmap 매개변수로 지정 *기본값 viridis
컬러막대: 컬러맵의 색깔이 어떤 값에 대응하는지 참조 정보 제공
fig, ax = plt.subplots(figsize=(10, 8))
sc = ax.scatter(ns_book8['발행년도'], ns_book8['출판사'],
linewidths=0.5, edgecolors='k', alpha=0.3,
s=ns_book8['대출건수']**1.3, c=ns_book8['대출건수'], cmap='jet')
ax.set_title('출판사별 발행도서')
fig.colorbar(sc) #scatter() 함수가 반환하는 객체 전달
fig.show()
06-2. 맷플롯립의 고급 기능 배우기
*4장에서 만들었던 ns_book7으로 실습

top30_pubs = ns_book7['출판사'].value_counts()[:30] #대출건수 상위 30위 출판사
top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index)
#출판사, 발행년도, 대출건수만 추출
ns_book9 = ns_book7[top30_pubs_idx][['출판사', '발행년도', '대출건수']]
#출판사와 발행년도 열 기준, 행 모은 후 대출건수 열 합하기
ns_book9 = ns_book9.groupby(by=['출판사', '발행년도']).sum()
ns_book9 = ns_book9.reset_index() #인덱스 초기화
ns_book9[ns_book9['출판사'] == '황금가지'].head() #황금기지 출판사 데이터만 확인
- 여러 개의 선 그래프를 그리고 싶다 ! → plot( ) 함수 여러 번 호출 !!
fig, ax = plt.subplots(figsize= (8, 6))
ax.plot(line1['발행년도'], line1['대출건수'])
ax.plot(line2['발행년도'], line2['대출건수'])
ax.set_title('연도별 대출건수')
fig.show()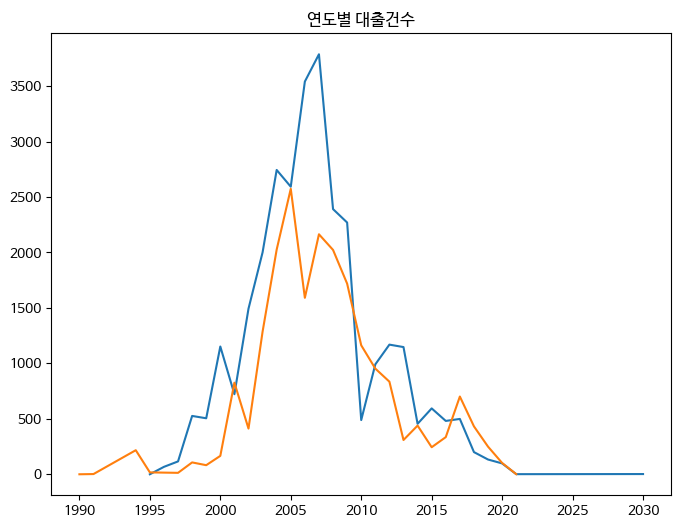
맷플롯립은 기본적으로 10개의 색 돌아가며 그래프 그림
→ 선 그래프가 10개 이상이면? 처음 색부터 반복 !
10개 이상 그릴 경우 선 그래프 구분하기 어려워짐 !!
→ 범례 추가하여 해결 !!!
fig, ax = plt.subplots(figsize= (8, 6))
ax.plot(line1['발행년도'], line1['대출건수'], label='황금기지') #label 추가
ax.plot(line2['발행년도'], line2['대출건수'], label='비룡소') #label 추가
ax.set_title('연도별 대출건수')
ax.legend() #legend() 메소드 호출
fig.show()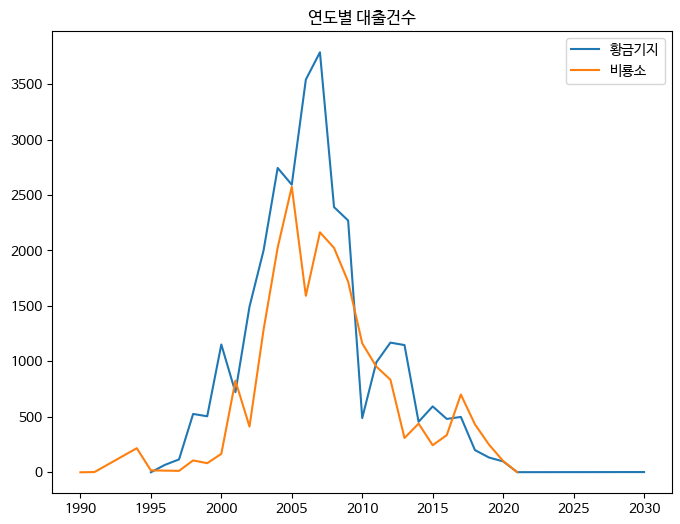
fig, ax = plt.subplots(figsize=(8, 6))
#반복문으로 5개의 선 그래프 그리기
for pub in top30_pubs.index[:5]:
line = ns_book9[ns_book9['출판사'] == pub]
ax.plot(line['발행년도'], line['대출건수'], label=pub)
ax.set_title('년도별 대출건수')
ax.legend()
ax.set_xlim(1985, 2025) #x축 범위 지정
fig.show()
set_xlim(최솟값, 최댓값) 메서드: x축 범위 지정
set_ylim(최솟값, 최댓값) 메서드: y축 범위 지정
- 스택 영역 그래프 그리기
스택 영역 그래프: 하나의 선 그래프 위에 다른 선 그래프를 차례로 쌓는 것
stackplot( ) 메서드 stackplot(x축의 값, 2차원 배열의 y축의 값)
발행년도에 따른 출판사별 대출건수 그래프 만들기
1. y축에 넣을 2차원 배열 만들기
2. x축에 넣을 리스트 만들기
3. 스택 영역 그래프 그리기
1. pivot_tabel( ) 메서드로 각 '발행년도' 열의 값을 열로 바꾸기
ns_book10 = ns_book9.pivot_table(index='출판사', columns='발행년도')
ns_book10.head()
('대출건수', 년도) 다단으로 열 구성
ns_book10.columns[:10]
2. '발행년도' 열을 리스트 형태로 바꾸기
top10_pubs = top30_pubs.index[:10]
year_cols = ns_book10.columns.get_level_values(1)get_level_values( ) 메서드: 다단으로 구성된 열 이름에서 선택한 항목만 가져옴
→ 다단으로 구성된 열에서 연도로 구성된 두 번째 항목만 가져옴
3. stackplot( ) 메서드로 스택 영역 그래프 그리기
fig, ax = plt.subplots(figsize=(8, 6))
ax.stackplot(year_cols, ns_book10.loc[top10_pubs].fillna(0), labels=top10_pubs)
ax.set_title('년도별 대출건수')
ax.legend(loc='upper left') #왼쪽 상단에 범례 표시
ax.set_xlim(1985, 2025)
fig.show()
- 하나의 피겨에 여러 개의 막대그래프 그리기
fix, ax = plt.subplots(figsize=(8, 6))
ax.bar(line1['발행년도'], line1['대출건수'], label='황금가지')
ax.bar(line2['발행년도'], line2['대출건수'], label='비룡소')
ax.set_title('연도별 대출건수')
ax.legend()
fig.show()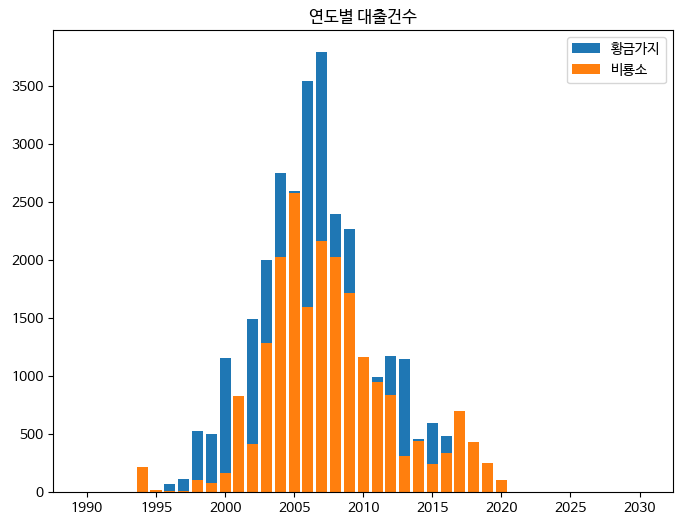
bar( ) 메서드 연이어 호출 시 먼저 그린 막대를 덮어 막대가 겹쳐짐!
→ 막대의 두께를 절반으로 줄인 후 x축에서 절반으로 줄인 막대 너비의 절반씩 떨어지도록 그리게 하여 해결 !!
막대 기본 너비 0.8
절반으로 줄인 너비 0.4
절반으로 줄인 너비의 절반씩 떨어지게 함 0.2씩 이동
fix, ax = plt.subplots(figsize=(8, 6))
ax.bar(line1['발행년도']-0.2, line1['대출건수'], label='황금가지', width=0.4)
ax.bar(line2['발행년도']+0.2, line2['대출건수'], label='비룡소', width=0.4)
ax.set_title('연도별 대출건수')
ax.legend()
fig.show()
- 스택 막대 그래프 그리기
스택 막대그래프: 막대그래프를 스택 영역 그래프처럼 위로 쌓은 막대그래프
bar( ) 메서드의 bottom 매개변수
height1 = [5, 4, 7, 9, 8]
height2 = [3, 2, 4, 1, 2]
plt.bar(range(5), height1, width=0.5)
plt.bar(range(5), height2, bottom=height1, width=0.5)
plt.show()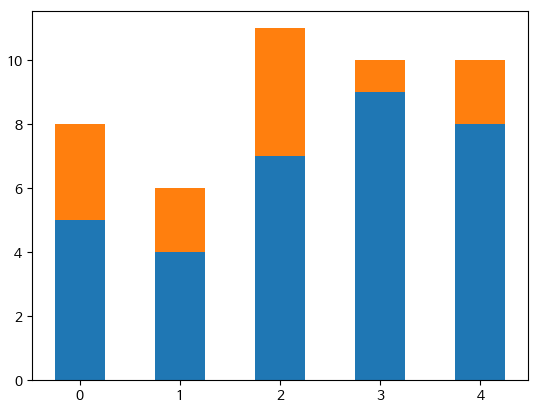
#리스트 내포를 이용하여 막대의 길이 누적해 놓고 그래프 그리기
height3 = [a + b for a, b in zip(height1, height2)]
plt.bar(range(5), height3, width=0.5)
plt.bar(range(5), height1, width=0.5)
plt.show()
- 데이터값 누적하여 그리기
comsum( ) 메서드 이용하여 값 누적
#상위 다섯 개 출판사의 2013년~2020년 대출건수
ns_book10.loc[top10_pubs[:5], ('대출건수',2013):('대출건수',2020)]
2013년 문학동네 6919.0 민음사 2219.0
ns_book10.loc[top10_pubs[:5], ('대출건수',2013):('대출건수',2020)].cumsum()
2013년 문학동네 6919.0 민음사 9138.0 (6919.0+2219.0) → 값이 누적된다 !
#ns_book10 데이터프레임 전체에 적용
ns_book12 = ns_book10.loc[top10_pubs].cumsum()
fig, ax = plt.subplots(figsize=(8, 6))
#인덱스 역순으로 반복해 그리기
for i in reversed(range(len(ns_book12))):
bar = ns_book12.iloc[i]
label = ns_book12.index[i]
ax.bar(year_cols, bar, label=label)
ax.set_title('연도별 대출건수')
ax.legend(loc='upper left')
ax.set_xlim(1985, 2025)
fig.show()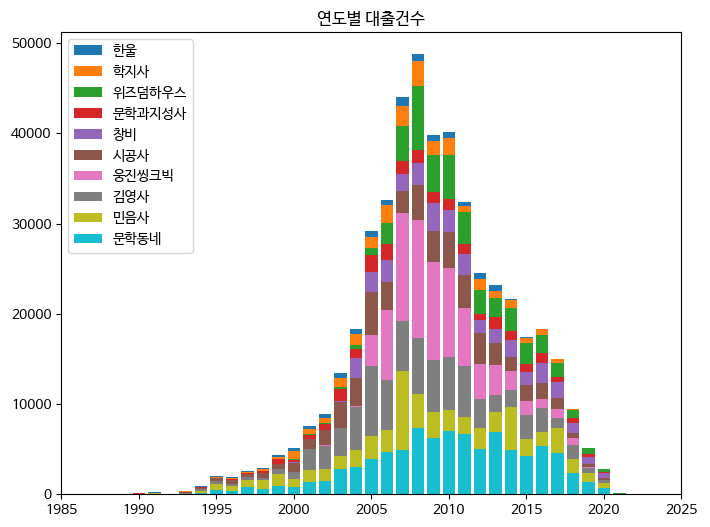
- 원 그래프 그리기
원 그래프(파이 차트): 전체 데이터에 대한 비율을 원의 부채꼴로 나타낸 그래프
pie( ) 메서드 labels 매개변수: 부채꼴 모양 위에 표시할 이름 전달
data = top30_pubs[:10] #상위 10개 출판사의 도서 개수 선택 저장
labels = top30_pubs.index[:10] #상위 10개 출판사의 인덱스 저장fig, ax = plt.subplots(figsize=(8, 6))
ax.pie(data, labels=labels)
ax.set_title('출판사 도서 비율')
fig.show()
선 그래프와 막대그래프보다 시각적인 구분 힘듦 → 잘못된 정보 제공하지 않도록 조심하기 !
#startangle = 90 으로 설정하여 12시 방향부터 원 그래프 그리기
plt.pie([10, 9], labels =['A 제품', 'B 제품'], startangle = 90)
plt.title('제품의 매출 비율')
plt.show()
autopct 매개변수: 파이썬의 % 연산자에 적용할 포맷팅 문자열 전달
→ '%d' 부채꼴 비율 정수로 표시
explode 매개변수: 떨어뜨리길 원하는 조각의 간격을 반지름의 비율로 지정
→ explode=[0.1]+[0]*9 첫 번째 조각 0.1, 나머지 0
fig, ax = plt.subplots(figsize=(8, 6))
ax.pie(data, labels=labels, startangle=90,
autopct ='%.1f%%', explode=[0.1]+[0]*9) #'%.1f%%' 소수점 첫째 자리까지만 표시
ax.set_title('출판사 도서 비율')
fig.show()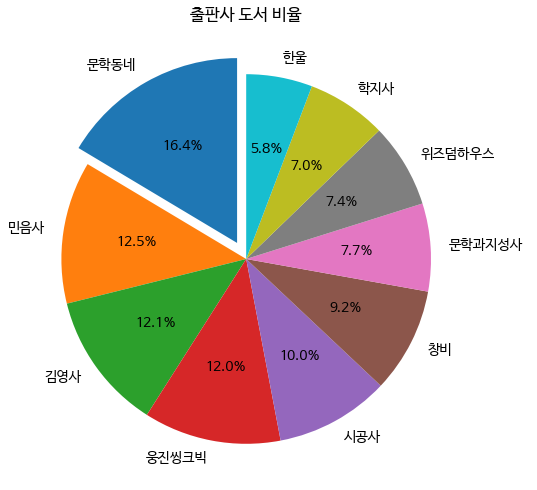
fig, axes = plt.subplots(2, 2, figsize=(20, 16))
#산점도 그리기
ns_book8 = ns_book7[top30_pubs_idx].sample(1000, random_state=42)
sc = axes[0, 0].scatter(ns_book8['발행년도'], ns_book8['출판사'],
linewidths=0.5, edgecolors='k', alpha=0.3,
s=ns_book8['대출건수'], c=ns_book8['대출건수'], cmap='jet')
axes[0, 0].set_title('출판사별 발행도서')
fig.colorbar(sc, ax=axes[0, 0])
#스택 영역 그래프 그리기
axes[0, 1].stackplot(year_cols, ns_book10.loc[top10_pubs].fillna(0))
axes[0, 1].set_title('연도별 대출건수')
axes[0, 1].legend(loc='upper left')
axes[0, 1].set_xlim(1985, 2025)
#스택 막대 그래프 그리기
for i in reversed(range(len(ns_book12))):
bar = ns_book12.iloc[i]
label = ns_book12.index[i]
axes[1, 0].bar(year_cols, bar, label=label)
axes[0, 1].set_title('연도별 대출건수')
axes[0, 1].legend(loc='upper left')
axes[0, 1].set_xlim(1985, 2025)
#원 그래프 그리기
axes[1, 1].pie(data, labels=labels, startangle=90)
axes[1, 1].set_title('출판사 도서 비율')
fig.savefig('all_in_one.png')
fig.show()
6주차 기본 숙제

6주차 추가 숙제
본문 속 정리 완료 !