[혼공분석] 3주차: 데이터 정제하기
공부하면서 느낀 건데 교재가 참 좋아요.. ~
학교에서 강의 들을 때 패키지, 메서드, 함수, 속성.. 뭐가 정말 많은데
깔금하게 정리가 안 돼서 공부하는 데 힘들었거든요..
막 query, groupby, agg... 이런 거 막 나오기 시작하고 제대로 정리가 안되어 있으면 쓸 수도 없단 말이죠...
갑자기 저번 학기 생각에 눈물이 날라 그러네...
이 교재는 함수랑 메서드 별로 정리도 다 있구 !! 교재 만족도 최상 ~~~~~
Chapter 03. 데이터 정제하기
03-1. 불필요한 데이터 삭제하기
데이터 정제: 데이터에서 손상되거나 부정확한 부분을 수정, 불필요한 데이터를 삭제하거나 불완전한 값을 교체하는 등의 작업

불러온 데이터에 NaN (= 결측치, 누락된 값) 확인 → 분석 전 다른 값으로 대체하거나 삭제 등의 데이터 정제 필요 !
열 삭제하기
- 슬라이싱
loc 메서드: 레이블 또는 불리언 배열로 데이터프레임의 행과 열 선택
df.loc[행:행, 열:열]
ns_book = ns_df.loc[:, '번호':'등록일자'] #전체 행, '번호'열에서 '등록일자'열까지
'번호' 열 과 '등록일자' 열 사이에 있는 결측치를 가진 열은 어떻게 제외할까?
불리언 배열! 로 원하는 열만 선택
*불리언: 참과 거짓, 두 가지 값을 가지는 자료형
원소별 비교를 통해 불리언 배열로 나타내기
ns_df.columns != 'Unnamed: 13' #넘파이 배열 반환
columns 속성: 판다스의 Index 클래스 객체로, 객체의 원소를 파이썬의 리스트처럼 숫자 인덱스로 참조 가능
ns_df.columns[0] → 번호
원소별 비교: 판다스 배열 성격의 객체는 어떤 값과 비교 시 자동으로 배열에 있는 모든 원소와 하나씩 비교
비교 연산자 != : 조건과 같지 않으면 True, 조건과 같으면 False
selected_columns = ns_df.columns != '부가기호'
ns_book = ns_df.loc[:, selected_columns]
ns_book.head()
- drop( ) 메서드 사용
drop( ) 메서드: 데이터프레임의 행이나 열 삭제
df.drop(삭제하려는 행 인덱스나 열 이름, axis=, inplace=)
axis = 0: 행 삭제 (기본값)
axis = 1: 열 삭제
inplace = False: 삭제 결과 반환 (기본값)
inplace = True: 현재 데이터프레임 자체 변경
ns_book.drop('주제분류번호', axis=1, inplace=True)
ns_book.head()
- dropna( ) 메서드 사용
dropna( )메서드: NaN이 하나 이상 포함된 데이터프레임의 행이나 열 삭제
df.drop(axis=, how=, thresh=, subset=[ ], inplace=)
axis = 0: 행 삭제 (기본값)
axis = 1: 열 삭제
how = 'any': 누락된 값이 하나 이상이면 삭제 (기본값)
how = 'all': 모든 원소가 누락된 행이나 열 삭제
thresh = n: 최소한의 누락되지 않은 값의 개수 지정
subset = [ ]: 삭제할 행과 열 리스트 지정 → 행 삭제하는 경우 열 인덱스 지정, 열 삭제하는 경우 행 이름 지정
inplace = False: 삭제 결과 반환 (기본값)
inplace = True: 현재 데이터프레임 자체 변경
ns_book = ns_df.dropna(axis=1)
ns_book.head()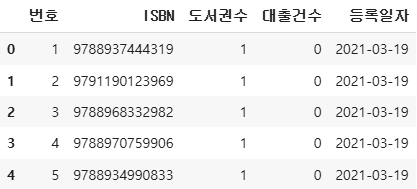
ns_book = ns_df.dropna(axis=1, how='all')
ns_book.head()
ns_book = ns_df.dropna(axis=1, thresh=100000)
ns_book.head()
ns_book = ns_df.dropna(subset=['주제분류번호'])
ns_book.head()
행 삭제하기
- drop( ) 메서드 사용
drop( )메서드: 데이터프레임의 행이나 열 삭제
df.drop(삭제하려는 행 인덱스나 열 이름, axis=, inplace=)
axis = 0: 행 삭제 (기본값)
axis = 1: 열 삭제
inplace = False: 삭제 결과 반환 (기본값)
inplace = True: 현재 데이터프레임 자체 변경
ns_book2 = ns_book.drop([0,1]) #axis 기본값 0이므로 생략
ns_book2.head()
-[ ] 연산자와 슬라이싱 사용 → 마지막 인덱스는 포함하지 않음 !
[n : m]: n번부터 m-1까지
[ : m]: 처음부터 m-1까지
[ n : ]: n번부터 끝까지
ns_book2 = ns_book[0:2] #인덱스 0부터 1까지
ns_book2.head()
-[ ] 연산자와 불리언 배열 → 마지막 인덱스는 포함하지 않음 !
selected_rows = ns_df['출판사'] == '한빛미디어'
ns_book2 = ns_book[selected_rows]
ns_book2.head()
-[ ] 연산자와 조건 → 불리언 배열을 만드는 조건을 바로 [ ] 연산자에 넣기
ns_book2 = ns_book[ns_book['대출건수']>1000]
ns_book2.head()
중복된 행 찾기
- duplicated( ) 메서드 사용
duplicated( )메서드: 중복된 행을 찾아 불리언 값으로 표시한 배열 반환
df. duplicated(subset=[ ], keep= )
subset = [ ]: 중복 검사를 위한 열 이름 또는 열 이름의 리스트 지정 → 미지정시 전체 열을 대상으로 중복 검사
keep = 'first': 처음 등장하는 행을 제외하고 중복된 행 True 표시
keep = 'last': 마지막으로 등장하는 행 제외하고 중복된 행 True 표시
keep = False: 중복된 모든 행 True 표시
sum(ns_book.duplicated()) #sum 함수는 True를 1로 인식, 중복된 행의 개수 세기 가능
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN'], keep=False)
ns_book3 = ns_book[dup_rows]
ns_book3.head()
그룹별로 모으기
- groupby( ) 메서드 사용
groupby( )메서드: 데이터프레임의 행을 그룹으로 모음
df. groupby(by=[ ], dropna= )
by= [ ]: 그룹으로 묶을 기준이 되는 열 또는 열 이름의 리스트 전달
dropna = True: by 매개변수에 지정된 열에 누락된 값이 있는 행 제외 (기본값)dropna = False: 누락된 값도 대상에 포함 → NaN 값도 표시
count_df = ns_book[['도서명', '저자', 'ISBN', '권', '대출건수']]
count_df.head()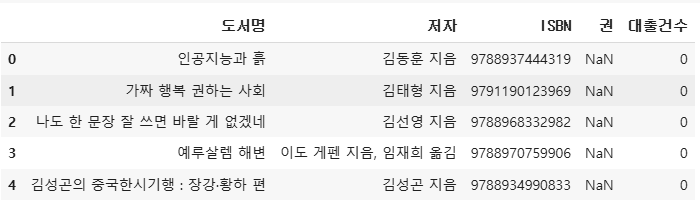
loan_count = count_df.groupby(by=['도서명', '저자', 'ISBN', '권'], dropna=False).sum()
#sum()으로 대출건수 합침
loan_count.head()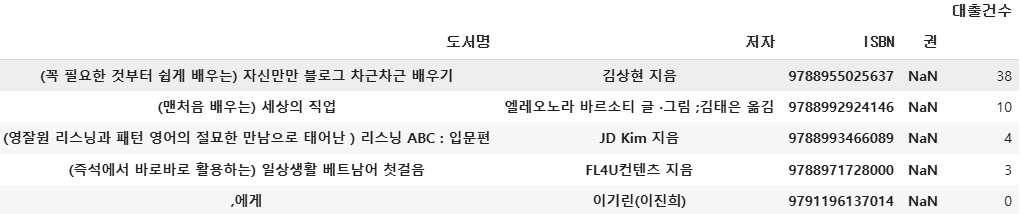
원본 데이터 업데이트하기
1. duplicated( ) 메서드로 중복된 행을 True로 표시한 불리언 배열 만들기2. 1번에서 구한 불리언 배열을 반전시켜 중복되지 않은 고유한 행을 True로 표시 → ~ 연산자 사용3. 2번에서 구한 불리언 배열을 사용해 원본 배열에서 고유한 행 선택 → copy( ) 메서드 사용 *copy( ) 메서드: 데이터프레임의 복사본 만들기
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN', '권'])
unique_rows = ~dup_rows
ns_book3 = ns_book[unique_rows].copy()sum(ns_book3.duplicated(subset=['도서명', '저자', 'ISBN', '권']))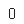
원본 데이터프레임 인덱스 설정
- set_index( ) 메서드 사용
set_index( )메서드: 지정한 열을 인덱스로 설정
df. set_index(인덱스로 지정할 열 또는 열 리스트, drop=, append= , inplace= )
drop = True: 인덱스로 지정한 열 삭제 후 인덱스에 추가 (기본값)drop = False: 인덱스로 지정한 열 삭제하지 않고 인덱스에 추가append = True: 기존의 인덱스에 새로운 인덱스 열 추가append = False: 기존의 인덱스에 추가하지 않음 (기본값)inplace = True: 현재 데이터프레임 자체 변경inplace = Fasle: 변경된 결과 반환 (기본값)
ns_book3.set_index(['도서명', '저자', 'ISBN', '권'], inplace=True)
ns_book3.head()
업데이트하기
- update( ) 메서드 사용
update( )메서드: 다른 데이터프레임을 사용해 원본 데이터프레임의 값을 업데이트, 다른 데이터프레임의 NaN 제외
df. update(업데이트에 사용할 데이터프레임, overwrite= )
overwrite = True: 원본 데이터프레임에 있는 모든 값 업데이트 (기본값)overwrite = False: 원본 데이터프레임에 있는 NaN 값만 업데이트
ns_book3.update(loan_count)
ns_book3.head()
- reset_index( ) 메서드 사용
reset_index( )메서드: 데이터프레임 인덱스 재설정
df. reset_index(level= , drop= , inplace= )
level = : 인덱스에서 제거할 열 이름 또는 순서 지정drop = True: 데이터프레임 열 이동하지 않고 삭제drop = False: 인덱스에서 제외된 열을 데이터프레임 열로 이동 (기본값)inplace = True: 현재 데이터프레임 변경inplace = False: 변경된 결과 반환 (기본값)
ns_book4 = ns_book3.reset_index()
ns_book4.head()
- equals( ) 메서드
equals( )메서드: 다른 데이터프레임과 동일한 원소를 가졌는지 비교
df. equals(비교하려는 데이터프레임) → 동일하면 True, 그렇지 않으면 False
03-2. 잘못된 데이터 수정하기
isna( )메서드: 데이터프레임의 요약 정보를 출력
isna(memory_type=, show_counts= )
memory_type = True: 열의 데이터 타입과 행 개수로 메모리 사용량 추정 (기본값)
memory_type = False: 메모리 사용량 미출력
momory_type = 'deep': 실제 메모리 사용량 계산
show_counts = True: 누락되지 않은 원소 개수 출력 (기본값)
show_counts = False: 누락되지 않은 원소 개수 미출력
ns_book4.info()
전체 행 개수: 384591
'도서명' 누락된 값이 없는 행 개수: 384188→ '도서명' 누락된 값: 384591 - 384188 = 403
누락된 값 처리하기
- isna( ) 메서드 사용
isna( )메서드: 누락된 값을 감지 → None이나 NaN일 경우 True
df.isna( )
ns_book4.isna().sum() #True 개수의 합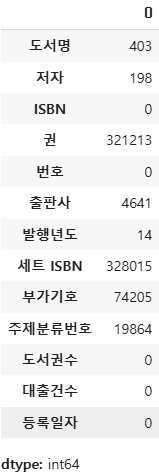
* notna( ) 메서드: 누락되지 않은 값 확인
ns_book4.loc[0, '도서권수'] = None
ns_book4.head(2)
ns_book4.loc[0, '부가기호'] = None #문자열을 저장할 수 있는 열은 None으로 표시
ns_book4.head()
np.nan
import numpy as np
ns_book4.loc[0, '부가기호'] = np.nan
ns_book4.head(2)
astype( )메서드: 데이터 타입 지정
df.astype(딕셔너리) → 데이터 타입 지정 시, 데이터프레임의 모든 열에 적용, 딕셔너리 전달 시 특정 열의 데이터 타입 변경
ns_book4.loc[0, '도서권수'] = 1
ns_book4 = ns_book4.astype({'도서권수': 'int32', '대출건수':'int32'})
ns_book4.head()
누락된 값 바꾸기
- loc, fillna( ) 메서드
fillna( ) 메서드: 데이터프레임에서 누락된 원소 값 채움
df.fillna(첫 번째 매개변수, method=, axis=, inplace= )
첫 번째 매개변수
: 스칼라인 경우 데이터프레임에서 누락된 값을 해당 값으로 채움
: 딕셔너리인 경우 열마다 '채울 값;으로 누락된 값 채움
: 시리즈인 경우 누락된 원소의 인덱스에 해당하는 시리즈 원소 값 채움
: 데이터프레임인 경우 누락된 원소의 열과 인덱스에 해당하는 데이터프레임 원소 채움
: 미지정시, method 매개변수로 누락된 값의 앞뒤에 있는 값으로 채움
method = 'bfill' / 'backfill': 누락된 값 이후에 등장하는 유효한 값으로 채움 (*df.bfill( ) )
method = 'ffill' / 'pad' : 누락된 값 이전에 등장하는 유효한 값으로 채움 (*df.ffill( ) )
axis = 0: 행 방향으로 누락된 값 채움 (기본값)
axis = 1: 열 방향으로 누락된 값 채움, bfill일 때 오른쪽 열의 값으로 왼쪽 열, ffill일 때 왼쪽 값을 오른쪽 열
inplace = True: 현재 데이터프레임 자체 변경
inplace = Fasle: 삭제된 결과 반환 (기본값)
set_isbn_na_rows = ns_book4['세트 ISBN'].isna() #누락된 값 찾아 불리언 배열 반환
ns_book4.loc[set_isbn_na_rows, '세트 ISBN'] = '' #누락된 값 빈 문자열로 변환
ns_book4['세트 ISBN'].isna().sum() #누락된 값 세기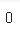
ns_book4.fillna('없음').isna().sum()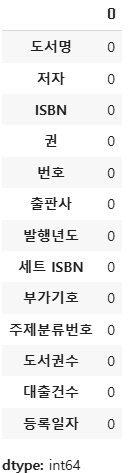
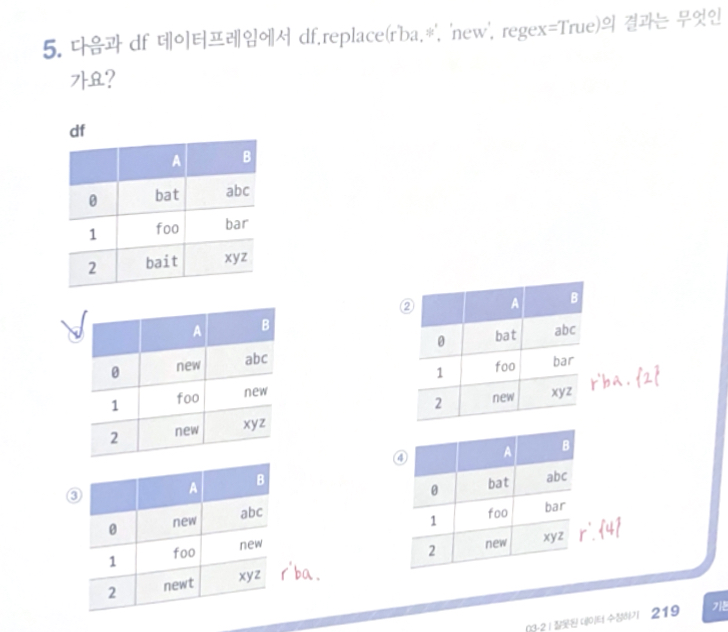
- replace( ) 메서드
replace( ) 메서드: 데이터프레임의 값을 다른 값으로 바꿈
df.replace(첫 번째 매개변수, 두 번째 매개변수, inplace= , regex= )
첫 번째 매개변수
: 찾을 값이 정수나 문자열, 정규 표현식인 경우 데이터프레임에서 값 찾아 두 번째 매개변수 값으로 바꿈
: 정수나 문자열, 정규 표현식의 리스트인 경우 값을 찾아 두 번째 매개변수 값으로 바꿈
: {열 이름: 찾을 값} 딕셔너리인 경우 지정한 열에서 '찾을 값'을 두 번째 매개변수 값으로 바꿈
: {열 이름: {찾을 값: 새로운 값}} 딕셔너리인 경우 '찾을 값'을 '새로운 값'으로 바꿈
두 번째 매개변수: 찾을 값이 정수나 문자열, 정규 표현식 또는 정규 표현식 리스트인 경우 대체할 값
inplace = True: 현재 데이터프레임 자체 변경
inplace = Fasle: 삭제된 결과 반환 (기본값)
regex = True: 정규 표현식 사용
regex = False: 정규 표현식 미사용 (기본값)
ns_book4.fillna('없음').isna().sum()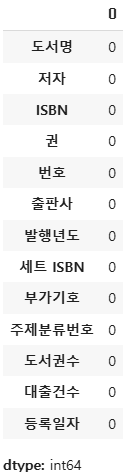
ns_book4.replace([np.nan, '2021'], ['없음', '21']).head(2)
ns_book4.replace({np.nan: '없음', '2021': '21'}).head(2)
ns_book4.replace({'부가기호': np.nan}, '없음').head(2)
ns_book4.replace({'부가기호': {np.nan: '없음'}, '발행년도': {'2021': '21'}}).head(2)
정규 표현식 (정규식): 문자열 패턴을 찾아서 대체하기 위한 규칙의 모음
ns_book4.replace({'발행년도': {'2021': '21'}})[100:102]
- 숫자 찾기: \d
\d\d\d\d → 네 자리
\d\d(\d\d) → 뒤의 두 자리를 하나의 묶음으로
*\D: 숫자가 아닌 다른 모든 문자에 대응하는 표현
ns_book4.replace({'발행년도': {r'\d\d(\d\d)': r'\1'}}, regex=True)[100:102]
- 문자 찾기: .
ns_book4.replace({'저자': {r'(.*)\s\(지은이\)(.*)\s\(옮긴이\)': r'\1\2'}, '발행년도': {r'\d{2}(\d{2})': r'\1'}}, regex=True)[100:102]
잘못된 값 바꾸기
ns_book4.astype({'발행년도': 'int64'})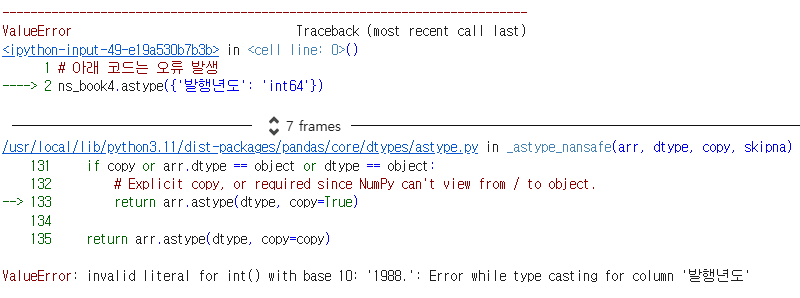

contains( ) 메서드: 시리즈나 인덱스에서 문자열 패턴을 포함하고 있는지 검사
str.contains(첫 번째 매개변수, case= , na= , regex= )
첫 번째 매개변수: 찾을 문자열 또는 정규 표현식
case = True: 대소문자 구분 (기본값)
case = False: 대소문자 미구분
na: 누락된 값을 가진 원소에 채울 값 지정 (기본 np.nan)
regex: 정규 표현식 사용 여부 결정 (기본값 True)
ns_book4['발행년도'].str.contains('1988').sum()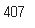
invalid_number = ns_book4['발행년도'].str.contains('\D', na=True)
print(invalid_number.sum())
ns_book4[invalid_number].head()
ns_book5 = ns_book4.replace({'발행년도':r'.*(\d{4}).*'}, r'\1', regex=True) *(\d{4}): 연도, r'\1': 첫 번째 그룹
ns_book5[invalid_number].head()
unkown_year = ns_book5['발행년도'].str.contains('\D', na=True)
print(unkown_year.sum())
ns_book5[unkown_year].head()
변환되지 않은 값 → 네 자리 숫자가 아닌 값, NaN
ns_book5.loc[unkown_year, '발행년도'] = '-1' #임의르 -1로 변환
ns_book5 = ns_book5.astype({'발행년도': 'int32'}) #발행년도 타입 정수형 int32로 변환
gt( ) 메서드: 데이터프레임의 원소보다 큰 값 검사
df.gt(비교하려는 값, axis= )
axis = 1: 열 방향 비교 (기본값)
axis = 0: 행 방향 비교
ns_book5['발행년도'].gt(4000).sum() #4000보다 큰 값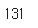
누락된 정보 채우기
아래 링크 참조 (추가적인 메소드 없어 정리 안 함!)
03-2.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
3주차 기본 숙제

3주차 추가 숙제